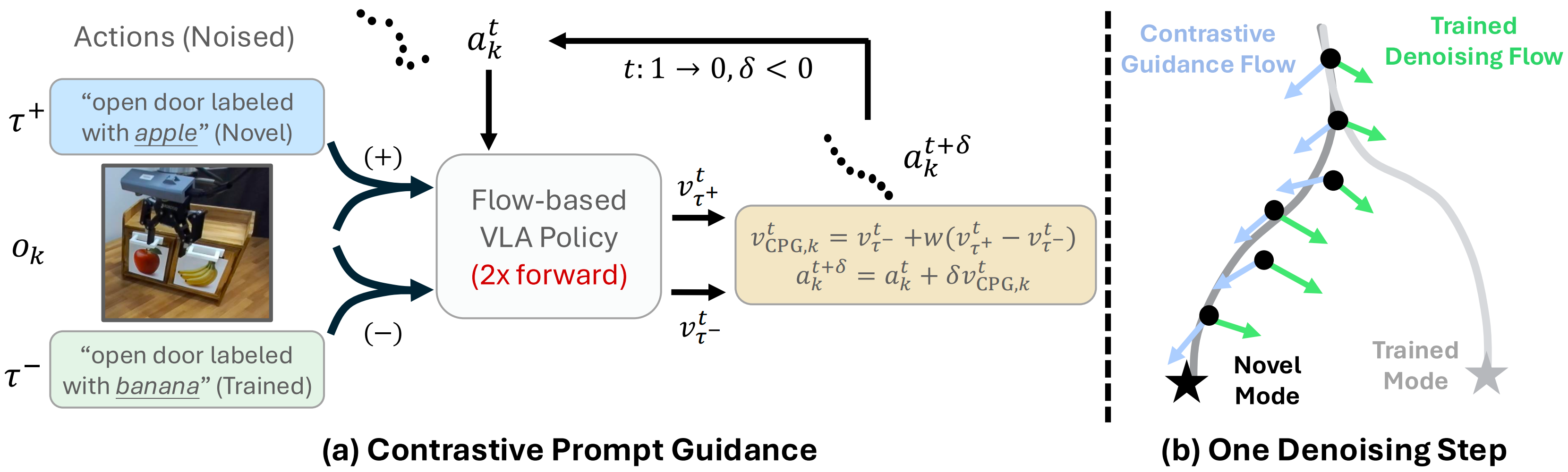
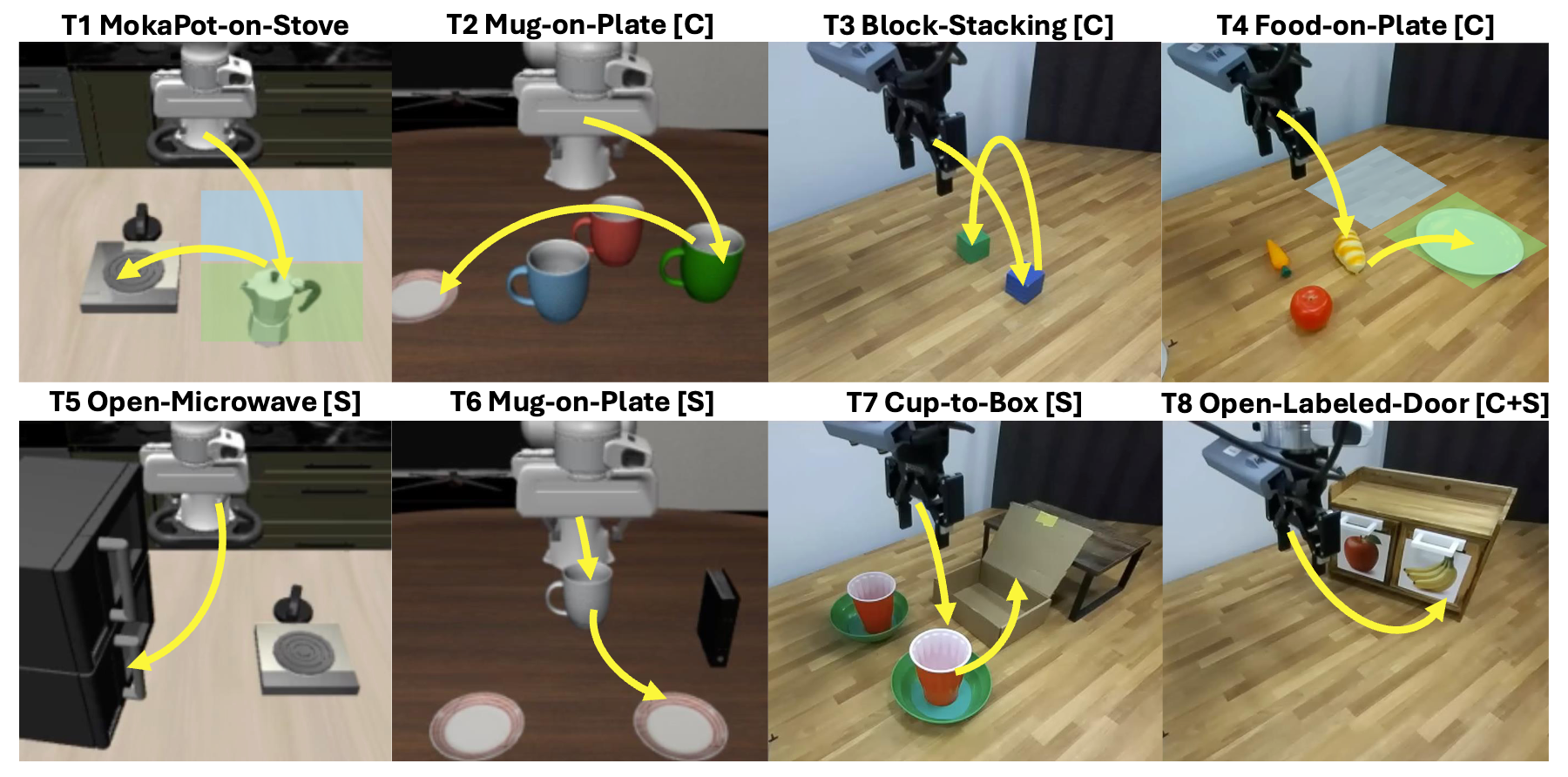
Have you ever post-trained a generalist vision-language-action (VLA) policy on a small demonstration dataset, only to find that it stops responding to new instructions and is limited to behaviors observed during post-training? We identify this phenomenon as lock-in: after low-data, supervised fine-tuning (SFT), the policy becomes overly specialized to the post-training data and fails to generalize to novel instructions, manifesting as concept lock-in (fixation on training objects/attributes) and spatial lock-in (fixation on training spatial targets). Many existing remedies introduce additional supervision signals, such as those derived from foundation models or auxiliary objectives, or rely on augmented datasets to recover generalization. In this paper, we show that the policy's internal pre-trained knowledge is sufficient: DeLock mitigates lock-in by preserving visual grounding during post-training and applying test-time contrastive prompt guidance to steer the policy's denoising dynamics according to novel instructions. Across eight simulation and real-world evaluations, DeLock consistently outperforms strong baselines and matches or exceeds the performance of a state-of-the-art generalist policy post-trained with substantially more curated demonstrations.